오늘은 네이버 금융 기사를 가져오려고 합니다. 그 중에서 한국콜마라는 기업에 대한 뉴스기사를 가져올 거에요.
며칠 전에 교양 수업에 한국콜마 대표님이 오셔서 강의하신 기억이 나서, 어떤 기업인지 궁금하니까 크롤링 해보겠습니다. ㅋ 참고로 코딩은 주피터로 하는 것을 추천드리며, 크롤링은 기본적으로 코랩에서는 작동하지 않는 점 참고하시면 될 것 같습니다.
주소 : finance.naver.com/item/main.nhn?code=161890
한국콜마 - 네이버 금융 : 네이버 금융
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com

오늘도 떨어졌군요... 아무튼 시작해보겠습니다.
1. 명확한 주소 찾아내기
일단 가운데 뉴스공시에 한국콜마에 대한 기사가 있습니다.
여기를 클릭해보면 주소가 finance.naver.com/item/news.nhn?code=161890가 뜹니다.
그런데 이게 우리가 찾는 뉴스공시 주소일까요? 좀 더 스크롤 하면

이렇게 1~10페이지를 클릭 할 수 있는데, 2페이지를 눌러보고 주소를 다시 확인해보세요!
finance.naver.com/item/news.nhn?code=161890 으로
1페이지와 2페이지 주소가 똑같은 것을 확인할 수 있습니다. 이러면 크롤링을 제대로 할 수가 없습니다.
따라서 우리는 저 뉴스 공시만 보여주는 페이지를 찾아야 합니다.
찾는 방법은 간단합니다.
1) 크롬에서 F12를 누르기
2) network 클릭

3)Name에 대충 가운데를 보면

news_news.nhn?으로 시작하는게 있는데 더블클릭을 하시면 됩니다.
4) 뉴스만 있는 페이지 확인

정말 뉴스만 있는 페이지를 확인할 수 있습니다. 이제 이 페이지의 주소는
finance.naver.com/item/news_news.nhn?code=161890&page=&sm=title_entity_id.basic&clusterId=입니다.
근데 자세히 보시면 page=&sm이라고 되어있는데, 뭔가 찝찝합니다. 이거는 2페이지로 넘어갔다가 다시 1페이지로 오면 finance.naver.com/item/news_news.nhn?code=161890&page=1&sm=title_entity_id.basic&clusterId= 로 살짝 바뀐 것을 확인할 수 있는데, 이 상태로 크롤링을 할 것입니다. page=1을 하는 이유는 나중에 2페이지 이상 한 번에 크롤링을 할 때, 주소에서 저 숫자 1만 바꿔주는 코딩을 해주면 되기 때문에 일부로 page=1을 나타나게 했습니다.
2. 웹 페이지 html가져오기
from bs4 import BeautifulSoup
import requests
url = "https://finance.naver.com/item/news_news.nhn?code=161890&page=1&sm=title_entity_id.basic&clusterId="
html = requests.get(url).content
bs = BeautifulSoup(html,'html.parser')
bs
- 이 페이지 전체의 html을 잘 가져오는 모습을 볼 수 있습니다. 대충 보니 td안에 기사 제목이 하나씩 들어가 있는 것을 확인할 수 있습니다.
all_td = bs.findAll('td', {'class' : 'title'})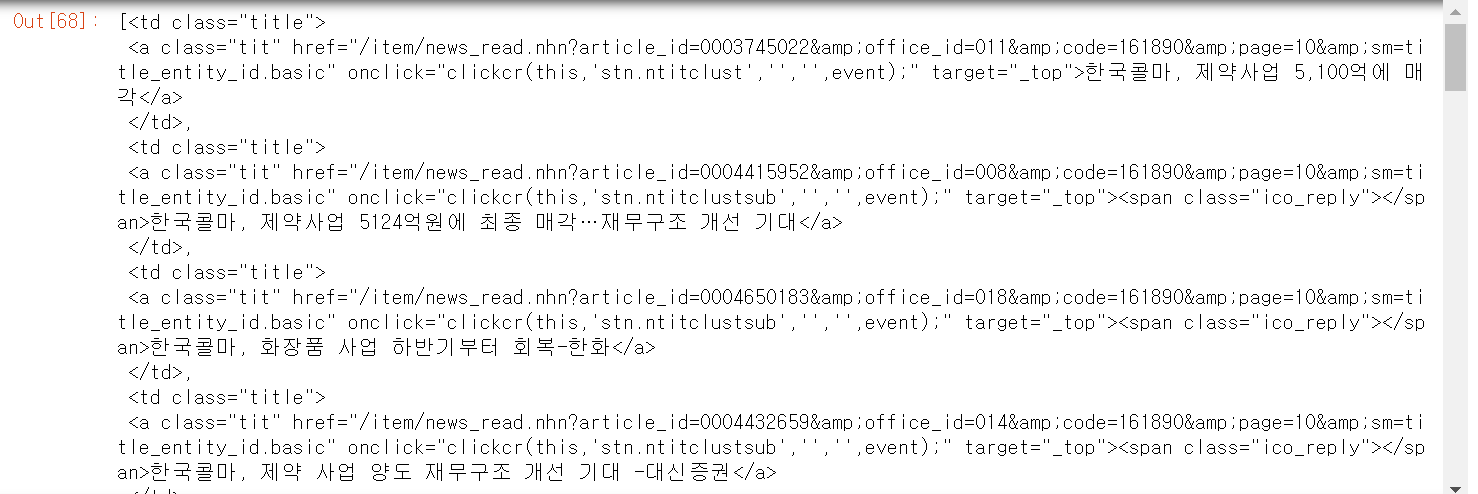
- 1페이지의 기사들이 td class = 'title'안에 다 들어가 있는 것을 확인할 수 있네요
for td in all_td:
print(td.find('a').get_text())
- 1페이지에 있는 기사를 다 가져왔습니다. 깔끔하네요. 여기서 만족할 수는 없죠. 2페이지 이상 가져와보겠습니다.
3. 2페이지 이상 기사 긁어오기
from bs4 import BeautifulSoup
import requests
titles = []
for page_num in range(1,11):
url_front = "https://finance.naver.com/item/news_news.nhn?code=161890&page="
url_last = "&sm=title_entity_id.basic&clusterId="
url = url_front + str(page_num) + url_last
html = requests.get(url).content
bs = BeautifulSoup(html,'html.parser')
all_tr = bs.findAll('td', {'class' : 'title'})
for tr in all_tr:
titles.append(tr.find('a').get_text())- 1~10페이지 기사를 다 긁어왔습니다.
네이버 금융의 경우 내가 코딩한 결과만으로 사이트에 접속해서 데이터를 가져올 수 있었는데요. 어떤 사이트는 자신이 사람임을 밝혀줘야 사이트 접속을 허용해줘서 우리가 크롤링 할 수 있습니다. 대표적으로 멜론사이트가 그렇습니다. 다음 포스팅에서는 웹사이트에게 내가 사람인 것을 보여주는 headers와 쿠키를 이용하는 방법을 알려드리겠습니다.
'웹 크롤링' 카테고리의 다른 글
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(4) - 반경을 이용한 검색 (2) | 2021.05.24 |
|---|---|
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(3) - 도로명 주소를 지번 주소로 변환 (0) | 2021.05.24 |
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(2) - 특정 범위 검색 (2) | 2021.03.31 |
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(1) - 키워드 검색 (9) | 2021.03.30 |
| 웹 크롤링 - 사람처럼 보이게 (feat. 멜론 크롤링) (0) | 2021.03.21 |



댓글