오늘 포스팅은
우클릭을 막은 네이버 블로그, 혹은 카페에 있는 글을 가져오는 것입니다.
기본적으로 네이버 블로그나, 카페를 크롤링 할 경우 BeautifulSoup를 이용하기보다 Selenium으로 하길 추천드립니다.
오늘 가져와볼 네이버 블로그는 https://blog.naver.com/ssagazyzzang/40000359630 입니다.
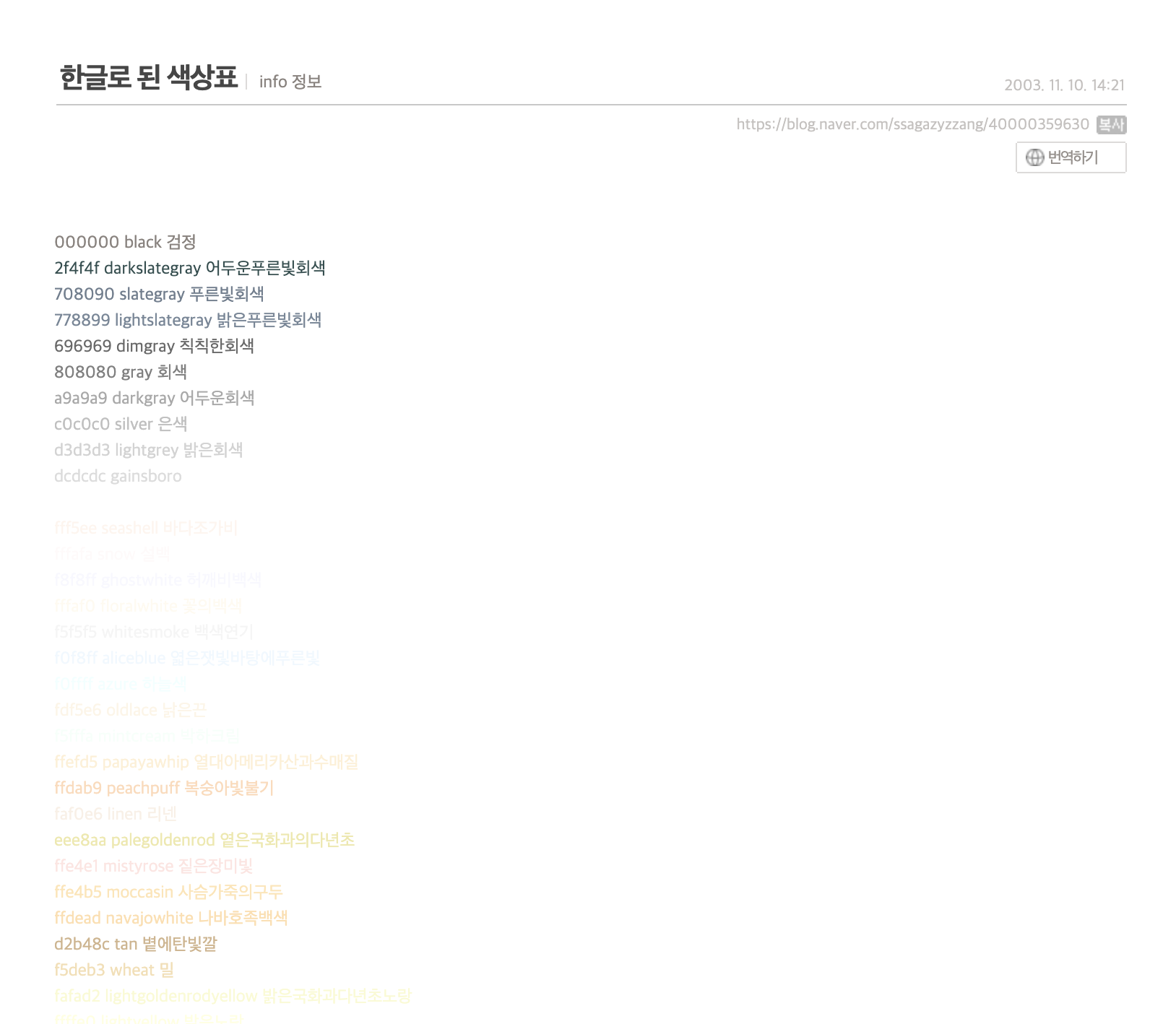
저는 영어로 된 색상표를 한글로 번역을 하고 싶은데요, 여기 네이버 블로거 한 분이 영어로된 색상을 한글로 번역해주셨네요.(무려 2003년 글...) 대략 개수를 세어봐도 60개가 넘어보이는데요, 영어로 된 색 이름과 한글로된 색이름을 같이 가져와 엑셀에 저장하겠습니다! 물론 우클릭이 안 됩니다. 그럼 시작하겠습니다.
1. 셀레니움으로 가져오기
from selenium import webdriver from bs4 import BeautifulSoup from urllib.request import urlretrieve from urllib.request import urlopen options = webdriver.ChromeOptions() options.add_argument('headless') ##크롬드라이브 안 켜지게 하려구... browser = webdriver.Chrome('chromedriver', chrome_options=options) url = 'https://blog.naver.com/ssagazyzzang/40000359630' browser.maximize_window() browser.get(url) bs = BeautifulSoup(browser.page_source, 'lxml') bs여기 간단한 코드를 짰습니다. 결과를 볼게요.
이 코드를 실행하기 전에 https://chromedriver.chromium.org/downloads에 가셔서 본인 os버젼과 크롬 버전에 맞는 파일을 다운받아서, 지금 돌리고 있는 파이썬 파일과 같은 폴더에 넣어주세요. 저는 mac os에 ChromeDriver 90.0.4430.24이거 쓰고 있더라구요. 크롬 버젼은 크롬을 켜서 설정에 가서 왼쪽 아래에 크롬 정보 누르면 알 수 있습니다.
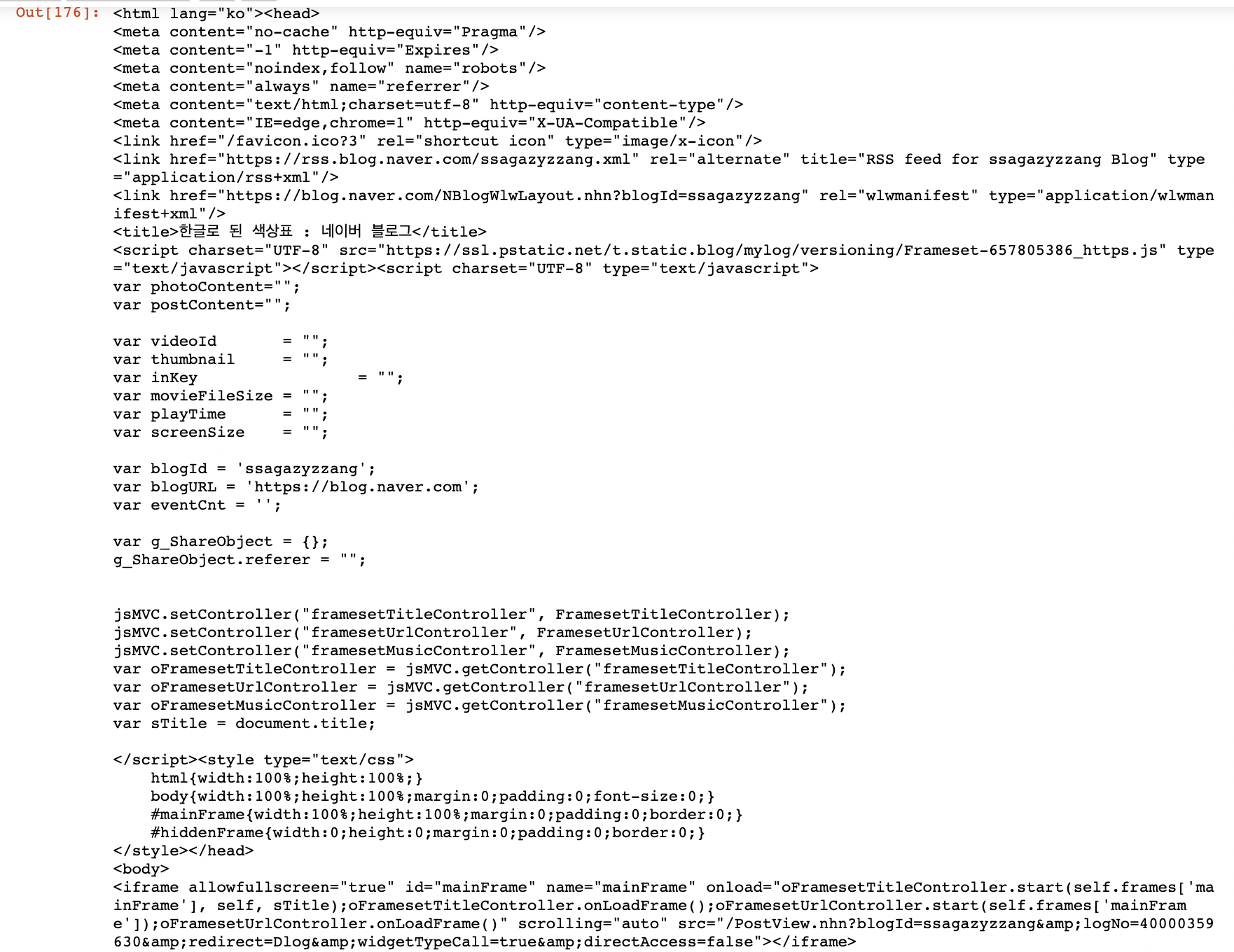
응...? 아무리 html을 뒤져봐도 색상이름이 적인 부분을 찾을 수 없네요????????????????? 뭔가 이상하죠? html을 다시 자세히 들여다 볼게요. 아.... 보니까 밑에서 4번째 줄에 iframe이라고 적혀있는게 보이네요. 결과를 iframe안에 저장해 놓았나봐요. 알고보니 대부분의 네이버 블로그와 카페는 우리가 가져올(크롤링할) 데이터를 iframe안에 둔다고 하네요. 그러면 iframe으로 selenium을 실행해볼게요
2. 셀레니움으로 가져오기(iframe 써서)
from selenium import webdriver from bs4 import BeautifulSoup from urllib.request import urlretrieve from urllib.request import urlopen import pandas as pd import os import re options = webdriver.ChromeOptions() options.add_argument('headless') driver = webdriver.Chrome('chromedriver', chrome_options=options) url = 'https://blog.naver.com/ssagazyzzang/40000359630' driver.maximize_window() driver.get(url) driver.switch_to.frame('mainFrame') bs = BeautifulSoup(driver.page_source, 'html.parser') bs이렇게 하니까 결과를 잘 가져오는 걸 확인했습니다. 결과를 마우스 스크롤을 해서 확인하다보면 중간쯤에 우리가 가져올 색상이 나와있는 부분이 있습니다. 이렇게요

3. 색 가져오기 (색 부분 html만 가져오기)
색이 "black 검정" 말고는 "font color"안에 다 들어가 있는 걸 확인할 수 있습니다. 그러면 그냥 font로 시작하는 것만 다 가져올게요!
a = bs.findAll('font') a결과를 볼게요. 엥????????????????? 왜 이렇게 결과가 많지??? 뭔가 이상함을 느껴야 합니다. 이상해서 https://blog.naver.com/ssagazyzzang/40000359630에 다시 들어가서 f12를 눌러서 확인해봅니다. 아.... 알겠네요....
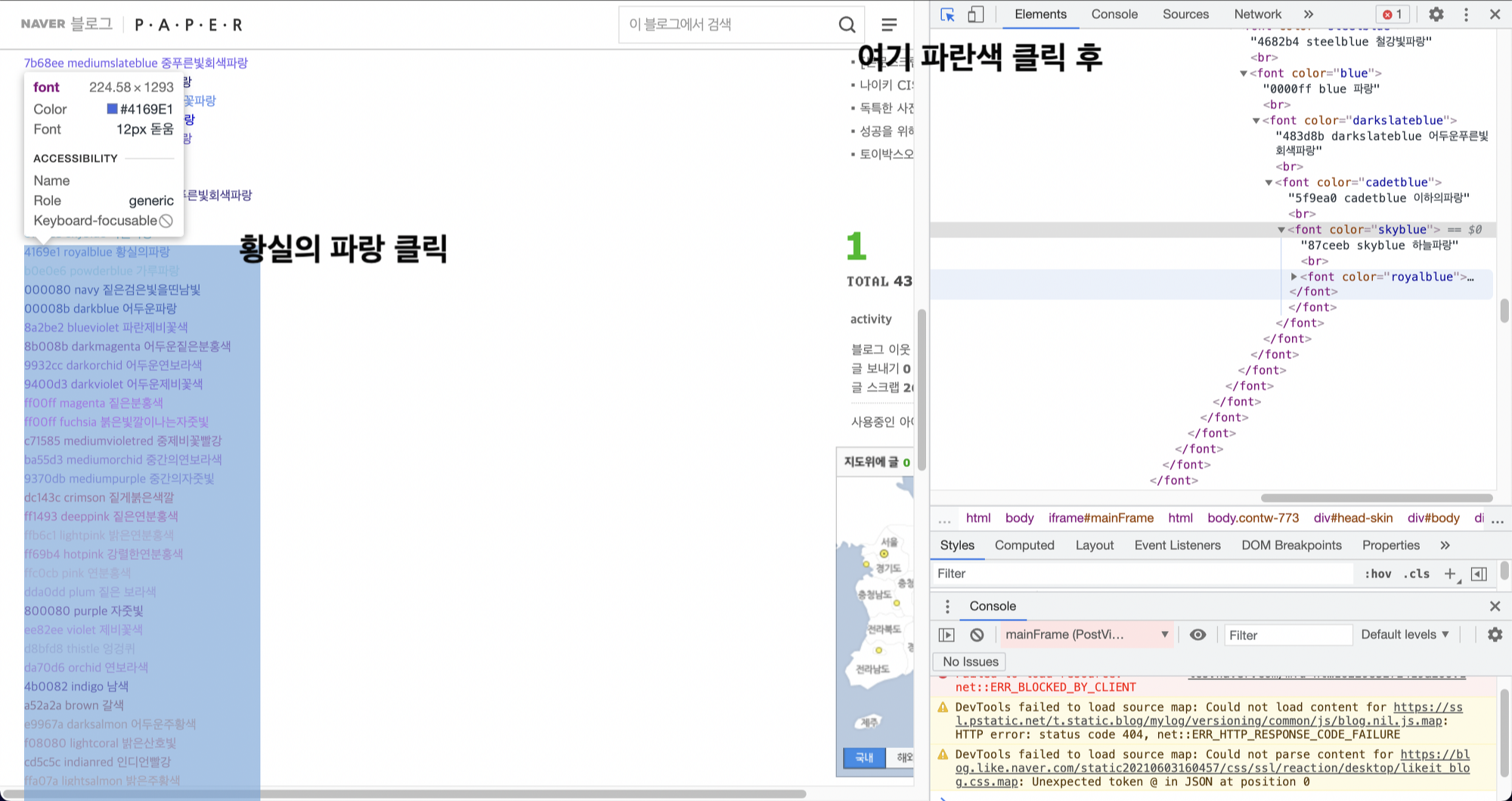
확인해보니까 저는 "황실의 파랑" 딱 하나만 선택하고 싶은데 이 색 아래 전체가 선택되는 걸 알 수 있습니다. 따라서 이 색 하나만 선택할 수는 없고, 이 색을 포함한 아래 전체를 한 번에 가져오네요. 그러면 머리를 써서 맨 위의 색(black은 font color안에 없으니까 제외)인 "어두운프른빛회색"을 선택하면 모든 색을 가져올 수 있다는 뜻입니다.
4. 색 이름 가져오기
여러분이 직접 a[0], a[1], a[2]의 결과를 확인해보세요. 각 결과 값 마다 다른점이 뭔지 아시겠나요? 네! 맨 첫 번째 색이 달라져요. a[0]에서 첫 번째 색은 어두운푸른빛회색, 두 번째 색은 푸른빛회색이에요. 그런데 a[1]에서 첫 번째 색은 푸른빛회색이네요. 어떤 식으로 작동하는지 느낌이 오시죠?
그럼 a[0]에서 첫 번째 색을 가져올게요
print(a[0].attrs['color']) print(re.sub('[0-9]','',a[0].text.split()[2]))
잘 나왔네요! 그러면 a[1]의 첫 번째 색인 "푸른빛 회색"을 가져올게요
print(a[1].attrs['color']) print(re.sub('[0-9]','',a[1].text.split()[2]))
잘 가져온 걸 확인했어요. 이제 for문을 돌려서 다 가져와봅시다
5. 색 전부 가져오기
en_cor = [] ko_cor = [] for i in range(len(a)): try: ko_cor.append(re.sub('[a-zA-Z0-9]*$','',a[i].text.split()[2])) ## 정규 표현식입니다! en_cor.append(a[i].attrs['color']) except: continue df = pd.DataFrame({ 'Eng' : en_cor, 'Kor' : ko_cor})df 안에 결과를 확인해보면 안타깝게도 3개 정도 이상 값과, dodgerblue라는 색의 한글 이름이 없네요. 꼭 크롤링 한 다음에 결과 값을 확인하셔서 내가 크롤링으로 제대로 가져왔는지?(3개 이상치), 원작자가 제대로 글을 썼는지?(dodgerblue색의 한글이름 없음) 확인하는 과정이 필수입니다.
이 포스팅의 목적이 웹크롤링으로 우클릭 뚫는 법과, iframe으로 가려진 html을 가져오는 것이 목적이었으므로 코드는 여기서 마치도록 할게요. 데이터 수정은 귀찮아섴ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
df.to_csv('hi.csv', index=False)그냥 이 정도 양의 데이터는 파이썬에서 어쩌구 저쩌구 하는 것보다 엑셀 파일로 저장하셔서 엑셀에서 수정하는 게 더 빠를 거라 생각합니다. 무조건 빠른 방법을 쓰세요!! ㅋㅋㅋㅋㅋㅋㅋ
'웹 크롤링' 카테고리의 다른 글
| 웹 크롤링 - [Python] 전기차 충전소 이용률 구하기 (2) | 2021.12.10 |
|---|---|
| 웹 크롤링 - [Python]파이썬으로 웹 사이트 이미지 저장 (0) | 2021.06.11 |
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(4) - 반경을 이용한 검색 (2) | 2021.05.24 |
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(3) - 도로명 주소를 지번 주소로 변환 (0) | 2021.05.24 |
| 웹 크롤링 - [Python]파이썬으로 카카오 맵 API 사용하기(2) - 특정 범위 검색 (2) | 2021.03.31 |




댓글